
|
Germanic Lexicon Project
Message Board
|
|
|
Author: Sean Crist (Swarthmore College)
Email: kurisuto at unagi dot cis dot upenn dot edu
Date: 2004-10-30 23:58:06
Subject: Re: New BT scribe checking in
>
> Hi Sean, Jim, and all :--
>
> Just started on the B/T supplement last night, and will post in a day or two.
Welcome aboard! Thanks for your help.
> OCR is reading two different diacriticals as acutes. See "freodom",
> at the beginning of line 13 on D0001 p.1; the first is definitely an o-acute, but
> I'm guessing the second is an o-long...yes? I'm treating them
> separately so far, and have 364 longs (A,AE,a,ae,i,o,u,y) to 65 acutes(U,a,e,i,o,u,y).
> For comparison, Cook's Cynewulf has tons of longs and no acutes at all.
Actually, that first acute in the instance of freódóm that you cite
is unusually sharply angled. Just glancing over that entry, I don't see any longs at all; all those diacritics are acute. I don't think I've seen any instances of long signs (macrons) on any Old English words in BT.
The longs, when they occur, are usually in Latin words and are a really totally horizontal line, not slightly sloped like the acutes. Some examples of longs are on page bt_b0250, e.g. in the entry for emn-líce (see the Latin word), further down on the same page under emtig (again, the Latin words), etc.
I haven't checked it carefully, but I think that what happened is that Bosworth included the long and short signs on the Latin words for the first few hundred pages which he wrote, but after Bosworth died and Toller took over the writing of the first volume, Toller didn't put those diacritics on the Latin words. The dictionary is not uniform in its editorial norms. When I was doing automated corrections of some of the source text abbreviations, I noticed that there were some cases where one variant was used in the first few hundred pages (probably by Bosworth), and another variant was used afterwards (probably by Toller).
Actually, if anyone knows of a big corpus of online Latin text with the short and long signs marked, I could use it to automatically add the signs to many of the Latin words in the parts of the text that have them. That would be one annoyance reduced.
> On odd characters, I have one at D0001 p.4, a-belgan entry, center of the next
> to last line, looking like a Old English z, which OCR called j. For now,
> it's "aboljen ERROR").
That one is &yogh; (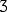 ). The letter yogh is found in later texts, like Middle English; I think it's also found in Scottish texts too.
). The letter yogh is found in later texts, like Middle English; I think it's also found in Scottish texts too.
> On consistancies: I vote for Roman numerals bold, and a space between numbers
> and letters (II a, 121 a).
OK, noted. We're two-to-one now on the spaces. :-)
Globally adding bold tags to the uppercase Roman numerals is on my to-do list. It looks like the general sense here was to bolden them.
> OCR skipped one line at the bottom of D0001 p.2, but otherwise has been very good.
--Sean
| Messages in this thread | Name | College/University | Date |
| New BT scribe checking in |
Mike Troy |
|
2004-10-30 21:22:23 |
| Re: New BT scribe checking in |
Sean Crist |
Swarthmore College |
2004-10-30 23:58:06 |